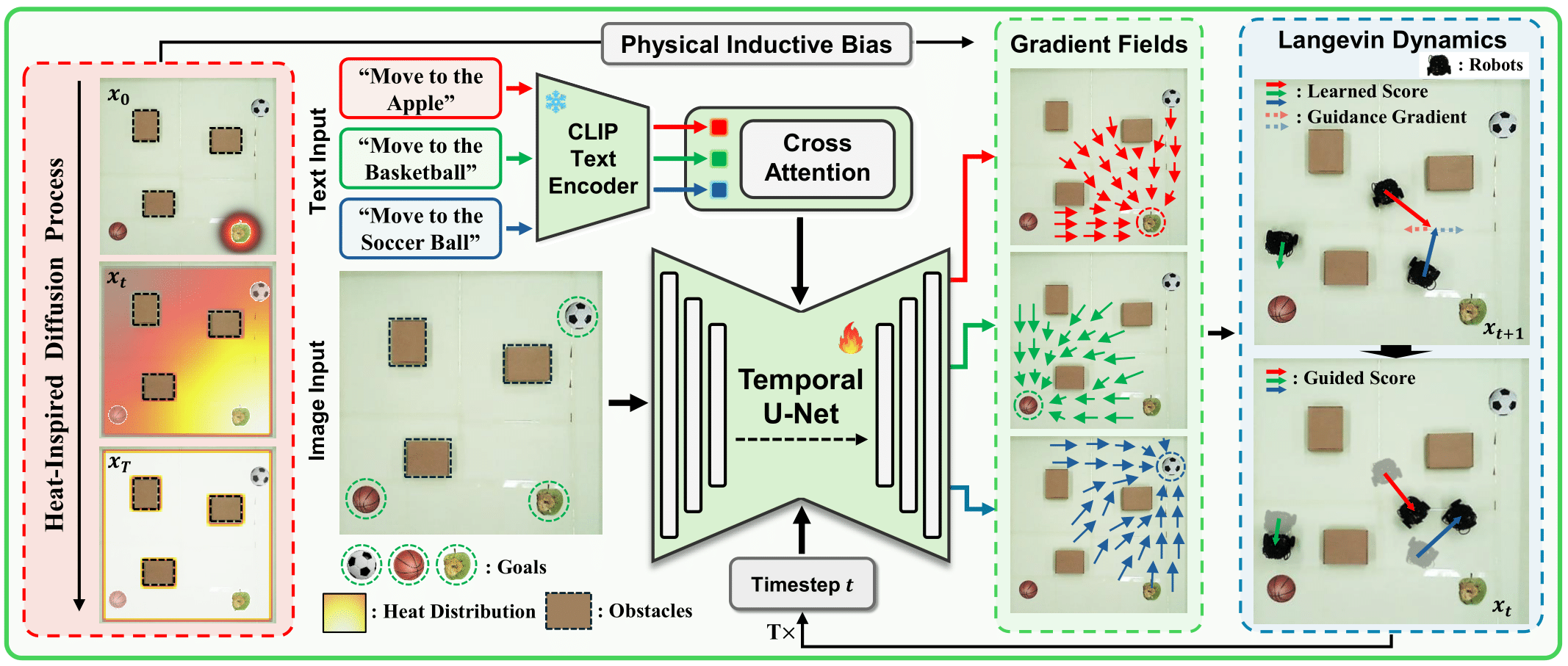
Diffusion models have recently emerged as powerful tools for robot motion planning by capturing the multi-modal distribution of feasible trajectories. However, their extension to multi-robot settings with flexible, language-conditioned task specifications remains limited. Furthermore, current diffusion-based approaches incur high computational cost during inference and struggle with generalization because they require explicit construction of environment representations and lack mechanisms for reasoning about geometric reachability.
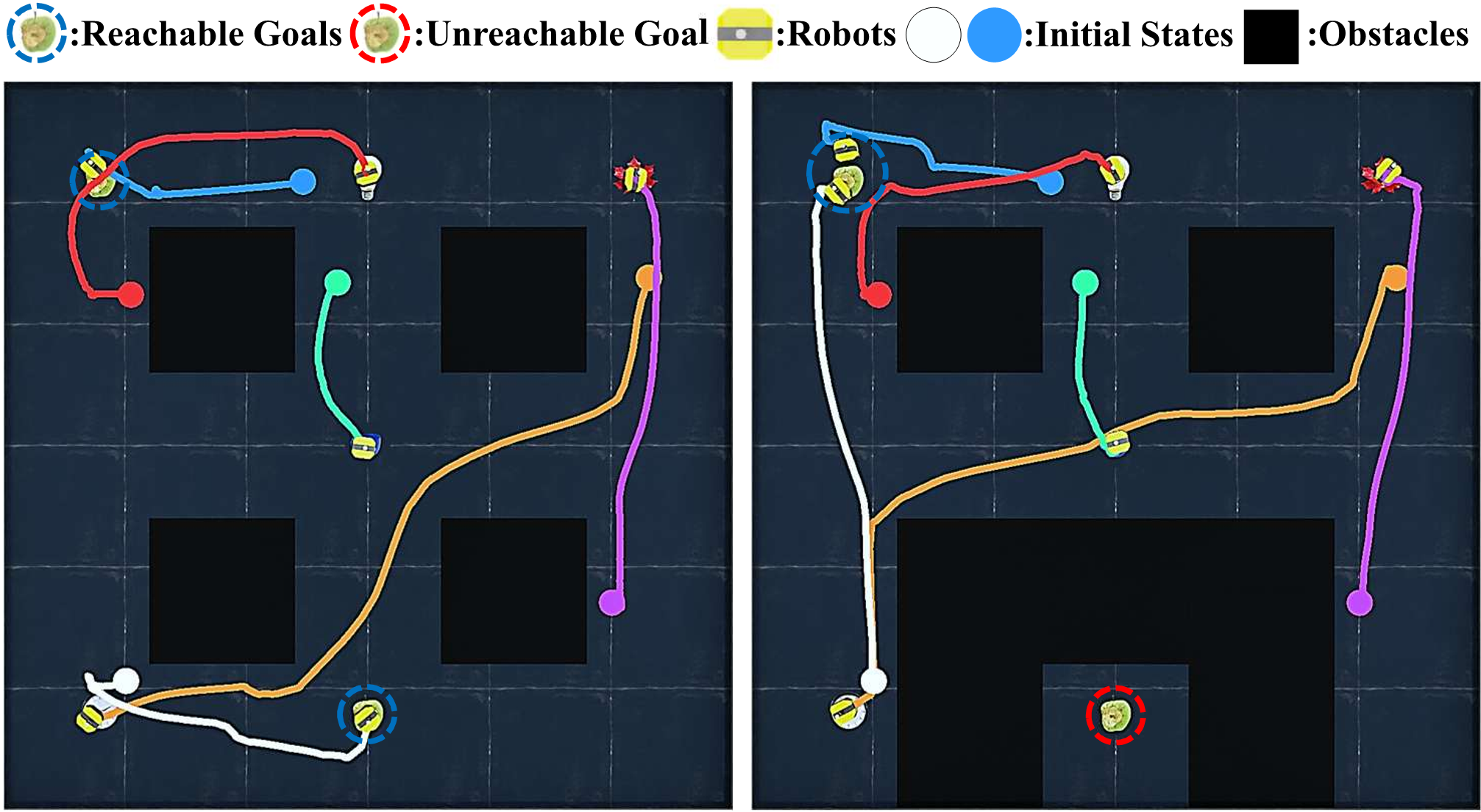
To address these limitations, we present Language-conditioned Heat-inspired Diffusion (LHD), an end-to-end vision-based framework that generates language-conditioned, collision-free trajectories. LHD integrates semantic priors from CLIP, a vision-language model (VLM), with a collision-avoiding diffusion kernel serving as a physical inductive bias that enables the planner to interpret language commands strictly within the reachable workspace. This naturally handles out-of-distribution (OOD) scenarios by guiding robots toward accessible alternatives that match the semantic intent, while eliminating the need for explicit obstacle information at inference time.
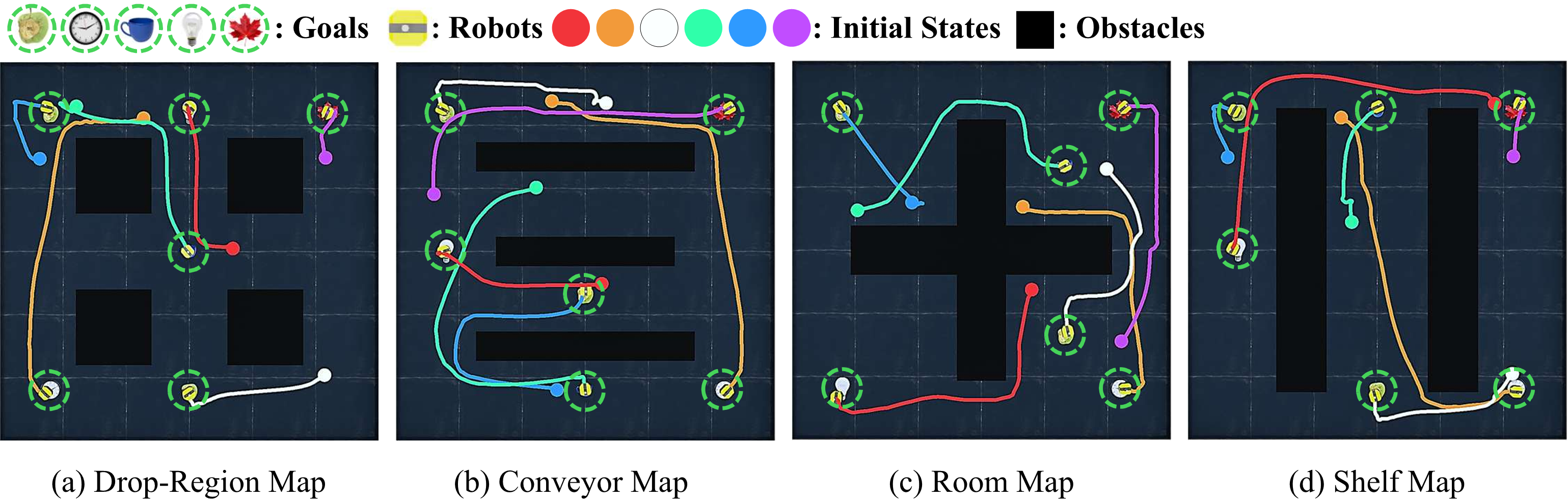
Extensive evaluations on diverse real-world-inspired maps, along with real-robot experiments, show that LHD consistently outperforms prior diffusion-based planners in success rate, while reducing planning latency.